Steven Kim, Dr. Elisa H. Barney Smith, Nishatul Majid

Introduction
- The purpose of this research is to recognize handwriting. We implemented the method for Bangla/Korean. This research work has been submitted to the International Conference of Frontier in Handwriting Recognition (ICFHR) 2020.
- Image recognition is often used for transcription, where storing data as a file is much more reliable than data written in a tangible object.
- In order to achieve high accuracy and productivity, we implemented a neural network named VGG-16, which provides Faster R-CNN and transfer learning.
- The Bangla network uses two individual networks in order to detect the character and the diacritics.
- The Korean network uses one network to detect the Hangul characters.
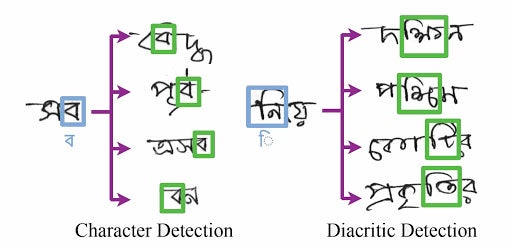
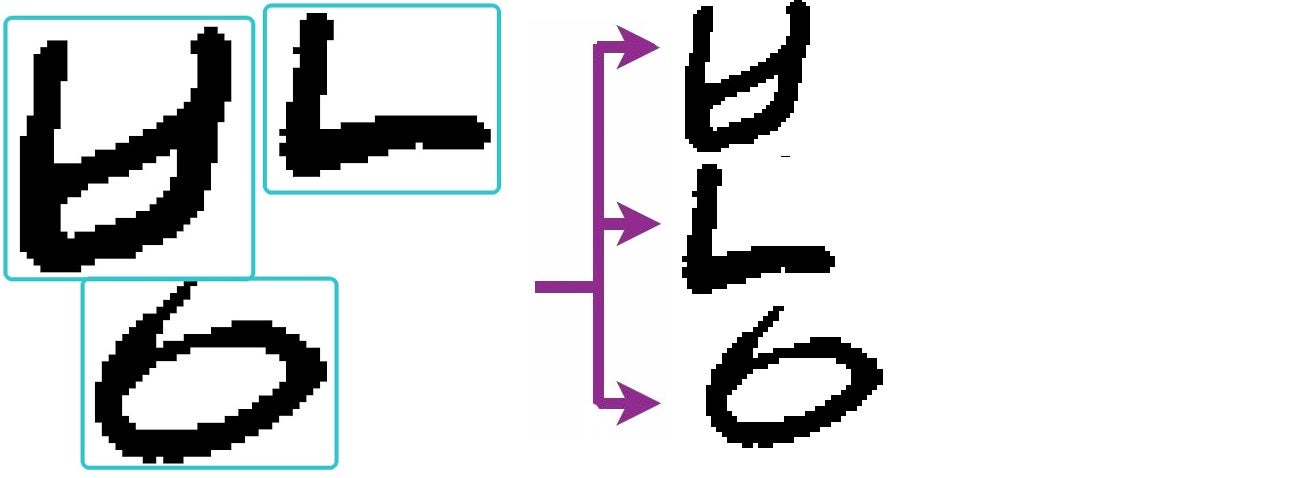
Image Detection Tools
Faster R-CNN
- Detects images of different sizes of boxes as figures 1 and 2.
- An efficient method for detecting objects that are overlapped with another object, which is often found within different types of handwriting.
VGG-16
- A pre-trained network which was converted into a character detecting network.
- Efficiently creates a network instead of building the network from scratch.
- Has 16 layers of convolutional network, developed by the Oxford research team VGG.
PE92 Korean Handwriting Database
Our Team used the PE92 Database that contains various compositions of handwritten Korean Characters. This was collected by POSTECH, funded by ETRI in 1992.
The Dataset contains 2350 classes with about 100 samples per class.
- Korean handwriting recognition was known as a difficult problem due to the existence of various compositions and patterns
- So far, researcher In-Jung Kim applied a convolutional neural network and achieved 92.92% accuracy using PE92.
Manual/Automated Tagging
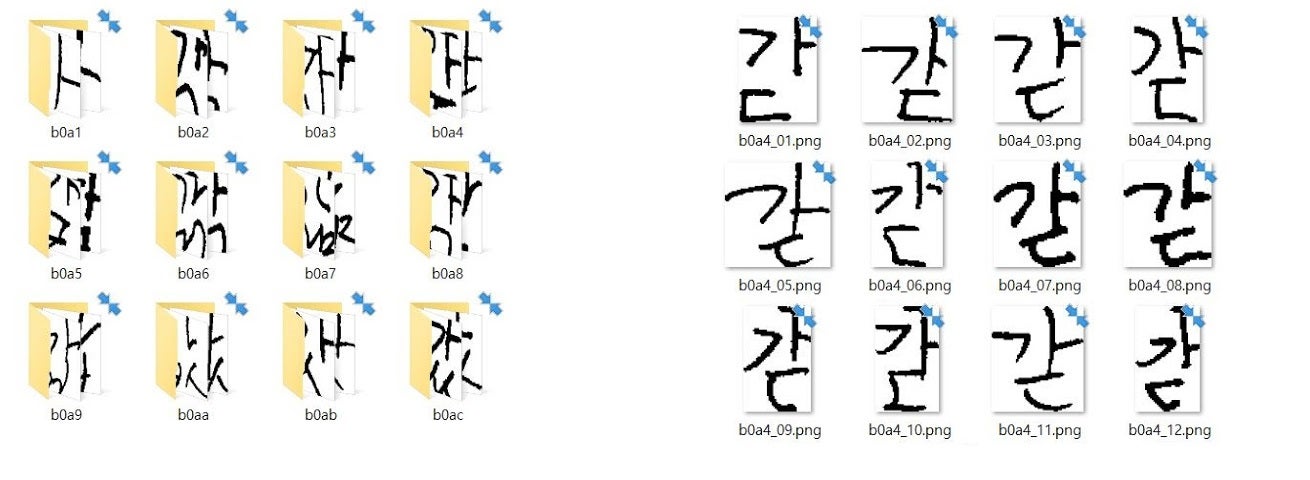
In order to teach a network how to recognize different objects, a process of tagging is required to draw a bounding box around each character and label its class. Covering every Korean composition is crucial, since we want the machine to recognize every possible case; Overall, we have manually tagged:
- 133 classes of different compositions
- 1468 samples
In the meantime, Dr. Barney Smith created an automated tagging framework. This framework uses existing tagged groundtruth in order to produce more groundtruth, which allowed us to obtain 133 classes with about 100 samples each.
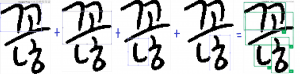
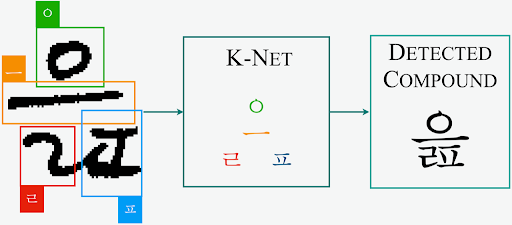
K-Net
Using the manual/automated tagging, we have created a network called “K-Net”. K-Net detects each individual characters and comes up with a compound of letter. In this research, we took into account of the individual and the compound detection accuracy, to make sure that the network is creating the combination in correct order.
Training /Testing Environment (R2 Cluster)
Using VGG-16 implies the fact that a cheap laptop without an external graphics card may take quite some time to finish the job. However, thanks to R2 Computer Cluster provided by the Research Computing Department, we were able to efficiently divide computational power by simply uploading the network and running it on the server.
Since we used a subset of the whole database, we were able to finish this process quickly, but with some loss of accuracy. Using the autonomous tagging, we got results of JRA (Jamo Recognition Accuracy) of 91.22%, and SRA (Syllable Recognition Accuracy) of 84.66%.
Table III: Korean Rcognition Results on PE92 Dataset
| Researchers | Methods | JRA | SRA |
|---|---|---|---|
| Park et al. [2] | MQDF | N.A. | 85.99% |
| Kim et al. [3] | DCNN | N.A. | 92.92% |
| Presented Approach (Using a Subset of PE92) | Character Spotting (Autonomous Tagging) | 91.22% | 84.66% |
| Presented Approach (Using a Subset of PE92) (Continued) | Character Spotting (Manual Tagging) | 86.22% | 79.23% |
Conclusion
This project is a derivative work from Nishatul Majid’s framework of Bangla Offline Handwriting Recognition. This is a new direction of approach for him.
Most languages write side to side, but Korean forms individual letters using different compositions then write from left to right.
Our maximum recognition accuracy was 84.66%. We haven’t done any post processing or finished implementing the whole dataset yet, which opens up more possibilities of this framework may be able to get a higher accuracy.
References
- N. Majid and E. H. Barney Smith, “Segmentation-Free Bangla Offline Handwriting Recognition using Sequential Detection of Characters and Diacritics with a Faster R-CNN” in International Conference on Document Analysis and Recognition (ICDAR), September 2019.
- Park, Gyu-Ro, In-Jung Kim, and Cheng-Lin Liu. “An evaluation of statistical methods in handwritten hangul recognition.” International Journal on Document Analysis and Recognition (IJDAR) 16.3 (2013): 273-283.
- Kim, In-Jung, and Xiaohui Xie. “Handwritten Hangul recognition using deep convolutional neural networks.” International Journal on Document Analysis and Recognition (IJDAR) 18.1 (2015): 1-13.
Additional Information
For questions or comments about this research, contact Steven Kim at stevenkim@u.boisestate.edu.