Best Practices
Management Strategies
Managing research data and the various files that contribute to your research efforts doesn’t happen just one time. Rather, file management it is an ongoing process that should be anticipated, planned for, and incorporated into your regular research efforts.
In general it can be helpful to think of research data management, and the resulting file management activities, as part of an overall research lifecycle.
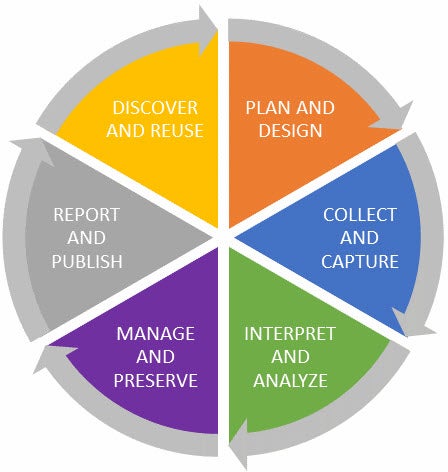
At different points in the lifecycle you will need to complete different types of file management activities. It’s a good idea to record your decisions in a written format, such as a lab manual or ReadMe file. Some common tasks for each stage of the lifecycle include:
- Plan and Design: Figure out your naming and folder organizational structure, and communicate this system to others working on the project.
- Collect and Capture: Implement and refine your organizational system. As the number of files and folders grow, does your naming convention and folder structure still make sense? If not, update it, making certain to record and inform anyone contributing materials to your system. Also, make certain to gather any needed metadata (descriptive information) when collecting or generating your research data.
- Interpret and Analyze: Continue to utilize your organizational system as new files are generated from your analysis. Consider creating a code book or other documentation system to capture specific steps taken and to ensure the reproducibility of your research.
- Manage and Preserve: Begin to think about the long term storage and preservation of your data. Revisit your original data management plan to determine if it has adequately addressed these issues. Do you need to update or add to your file naming system, such as by adding dates? Do you need to convert your files into accessible formats? Have you created a ? Have you contacted the Library for help identifying an appropriate permanent repository for your data?
- Report and Publish: In addition to most federal funders, publishers are now requesting that researchers share the data supporting their publication. Check with your chosen journal to see what requirements they have. Also be certain to review the publishing agreement regarding any research data you submit to the publisher. If you need help reviewing the agreement and understanding your author rights, contact the ScholarWorks staff (208-426-2581 or scholarworks@boisestate.edu). Non-sensitive data can also be published in ScholarWorks.
- Discover and Reuse: Once your data has been fully curated, archived, and published, other researchers should be able to find and utilize your data set. Make certain a DOI has been issued for your work so that it can be cited by others and reported to any funders who sponsored your work.
Human Component of File Management
It’s important to recognize that file management requires a committed effort throughout the life of the data. However, often these activities are not seen as important to the research process, prompting team members to put off critical organization work. To make certain everyone working on a research project contributes to creating an effective organizational system, try some of these strategies.
- Start at the top: Establish a top-level expectation that an organizational structure will be developed and utilized throughout the lifecycle of a project. Team Leaders can do this by purposefully incorporating file management into plans, scheduling check-in times, ensuring adequate resources and training, and assigning organizational duties to specific individuals.
- Check for needed resources: Determine if the individuals involved in managing a project’s file system have the necessary information, guidelines, training, tools, or other resources to efficiently fulfill these duties. Are related policies and procedures easily accessible and understandable to enable efficient use? Does everyone have the necessary skills, including knowing how to capture metadata, to manage project files? Do you need a budget or other funded resources to improve this work? Contact Library staff for help in determining if a data management budget would be appropriate for your project.
- Ensure accountability: To make certain all team members have a common understanding of what is expected when managing files and folders, consider implementing an acknowledgment or certification process. This will provide an initial verification that everyone understands how to utilize any organizational system or tools that have been established. This can be especially useful when working with student assistants. These sorts of verifications can be part of their employee file and included in discussions when concerns arise. During regular check-ins, monitor compliance with your initial organizational system. If modifications are needed, be sure that everyone is informed about these changes.
- Utilize built in tools: Some tools allow you to auto generate metadata or create file names following a certain structure. Investigate the tools you are using to see if such features exist. A small initial investment at the beginning of a project can result in long term efficiencies.
File Formats
Managing research data and the various files that contribute to your research efforts doesn’t happen just one time. Rather, file management it is an ongoing process that should be anticipated, planned for, and incorporated into your regular research efforts.
In general it can be helpful to think of research data management, and the resulting file management activities, as part of an overall research lifecycle: plan and design, collect and capture, interpret and analyze, manage and preserve, report and publish, discover and reuse.
At different points in the lifecycle you will need to complete different types of file management activities. It’s a good idea to record your decisions in a written format, such as a lab manual or ReadMe file. Some common tasks for each stage of the lifecycle include:
- Plan and Design: Figure out your naming and folder organizational structure, and communicate this system to others working on the project.
- Collect and Capture: Implement and refine your organizational system. As the number of files and folders grow, does your naming convention and folder structure still make sense? If not, update it, making certain to record and inform anyone contributing materials to your system. Also, make certain to gather any needed metadata (descriptive information) when collecting or generating your research data.
- Interpret and Analyze: Continue to utilize your organizational system as new files are generated from your analysis. Consider creating a code book or other documentation system to capture specific steps taken and to ensure the reproducibility of your research.
- Manage and Preserve: Begin to think about the long-term storage and preservation of your data. Revisit your original data management plan to determine if it has adequately addressed these issues. Do you need to update or add to your file naming system, such as by adding dates? Do you need to convert your files into accessible formats? Have you created a ? Have you contacted the Library for help identifying an appropriate permanent repository for your data?
- Report and Publish: In addition to most federal funders, publishers are now requesting that researchers share the data supporting their publication. Check with your chosen journal to see what requirements they have. Also be certain to review the publishing agreement regarding any research data you submit to the publisher. If you need help reviewing the agreement and understanding your author rights, contact the ScholarWorks staff (208-426-2581 or scholarworks@boisestate.edu). Non-sensitive data can also be published in ScholarWorks.
- Discover and Reuse: Once your data has been fully curated, archived, and published, other researchers should be able to find and utilize your data set. Make certain a DOI has been issued for your work so that it can be cited by others and reported to any funders who sponsored your work.
File/Folder Ownership and Access
Do I have to have a structure set up at the beginning or is it OK to develop one as we go along?
Just as with other parts of your research project, developing well thought out plans before you start working can help you identify specific strategies to use, needed resources, and potential barriers to success. Similarly, designing a file organization and naming structure before you begin collecting and generating data provides a solid foundation for managing your data. However, a plan is just a starting place. As the amount of files increase and your project progresses, you will want to revisit and revise your original structure based on your updated needs. It’s important to plan for this updating and to think of it as an iterative process which develops and evolves along with your project.
What do you mean “iterate your organizational structure”?
Unlike ad hoc organizational systems which are created randomly only when files are saved, a planned organizational system is conceptualized prior to creating research files. Once the system is in use, the team should thoughtfully evaluate what is or is not working, making needed modifications. These review and revision iterations should take place on a regular basis, building upon what has been learned from previous experiences.
How often should I review the organization, ownership, naming of my files?
Although there is no specific requirement or timeline for reviewing your research files, it is important to plan for and follow through on a regular review. If it is hard to determine when to do this review, schedule an annual review beginning one year after the start of your project. Or if you expect that a large number of files will be created for your project, consider identifying a threshold number of files, such as 10% of the estimated files you are expecting to create during the life of the project, to trigger a review of your system. This threshold could also be based upon numbers of individuals working with the files, duration of the project, how many changes you are expecting with the files, or complex versioning of the files.
What training or support do I and/or my team need to effectively manage our files?
The level of training needed will depend on the type of data you are working with, the methodology and tools used to gather the data, and the complexity of the organizational system needed to properly manage your data. In general, individuals working with research data should have a basic understanding of data management best practices, including managing access to files, retaining sufficient descriptive information about the data, and long term data preservation. Additionally, individuals working with the research data should be familiar with the unique conventions developed for naming and organizing files for the research project and be prepared to allocate the time needed to comply with these expectations.
If you are working with individuals who are unfamiliar with common data management practices, such as student researchers, it is recommended that they receive as a minimum basic data management training and if appropriate, have access to related data management documentation. Additionally, training is most effective when individuals are able to immediately apply practices to an active research project.
File/Folder Naming Conventions
How do I name my files and folders?
File names should describe the content of the file in a uniquely identifiable manner as this will aid in search and discovery within a folder or directory. They should contain information about the project or study, researcher, location, date, and data type. Additional considerations could include conditions under which data was collected and, if necessary, version number of the file. Folder names should also be uniquely identifiable and describe the content of the folder as this will aid in search and discovery within a directory.
What are some of the things I should consider?
Many systems use spaces to parse text strings, so consider using an underscore (_), a dash (-), or capital letters to separate parts of your file name. If your file name will be used as part of a URL, use dashes instead of underscores, as underscores can be difficult to see in URLs. Avoid using other special characters (~ ! @ # $ % ^ & * ( ) + = [ ] { } ‘ “) when naming files. When using a number as part of a file name, use the two-digit version (01 instead of 1) unless it is a year or other number with more than two digits. While the file name needs to include information relevant to identifying the file, keep in mind that some operating systems and software platforms may have restrictions on the number of characters in a file name. If you are including a date as part of the file name, start with the year (YYYY) and then move to month and/or day (YYYYMMDD). This will help your files stay in chronological order. If a personal name is included as part of the file name, use the last name first, followed by initials (SmithMA).
For folders, it is useful to set up a directory structure that provides information like the project title, date, and a unique identifier. Common best practice is to have no more than three levels of folders to aid in folder and file discovery, but you may need more. Individual folders within the directory can be set up by researcher, date, location, or whatever makes the most sense for your project.
Do I need machine-readable file and folder names? Where are you sending these files and do they have character limits? How do file names impact sorting and discovery?
If you need your file and folder names to be machine readable (E.g., you want to use a computerized system to query data you have in certain files), there are additional considerations: use lowercase letters instead of uppercase and use underscores or dashes to separate components of your file or folder name. If your project includes a large number of files and folders, think about naming them in a manner that will allow for appropriate sorting. Consider starting your file and folder names with the most general components and move to more specific ones later on since they will be grouped together based on the first few components.
How should I make sure my team follows my file and folder naming plan? How do I make sure that my naming schema makes sense to others?
To ensure that your team follows your naming plan, make rational decisions about naming schema and discuss your reasoning with your team members. Document the agreed-upon plan so that all team members will have specifics to refer to when questions arise and will understand the schema you’ve chosen makes sense for the project.
What if I’m sort of consistent in my file naming practices?
To avoid inconsistency when naming files, team members should refer back to the documented file naming schema when unsure. It can be helpful for the team leader to review the file naming schema chosen a few weeks or months into the file creation part of the project to determine the usefulness of the schema and make any necessary changes. Any changes made need to be documented and communicated to the rest of the team.
Who needs access to my files and do I need to provide simultaneous access?
Depending on where in the system your folders are located, you may need to specify who has access (shared network drives, Google Drive, etc.). Consider keeping access limited to the fewest number of people that actually need access to avoid unnecessary or accidental folder or file edits or deletions. Unlike the common difficulties when multiple team members are trying to access the same file, it should not be a problem for more than one team member to access a particular folder at the same time, regardless of which system is in use (Windows, Mac, Google Drive, etc.).
Where in my folder structure should I include a “ReadMe” file?
If you are documenting your folder/file structure in a “ReadMe” file, this file should be located in the top-level folder so that it will be visible and accessible to all team members.
Why would I want to or need to access something? How do I figure out what my access needs will be over time?
Your need to access materials related to a project will depend on your role within the team. The team leader should have a clear knowledge of which team members have access to which folders and files as well as the reasons why throughout the life of the project and this should be documented within the main project folder. The team leader should follow data access policies that were described in the original data management plan to the best of their abilities. If changes to access are necessary, they should be documented in the data management plan and the “ReadMe” document(s) associated with the project.
File Storage
Consider OIT resources for File Storage:
- Data at Boise State University is categorized according to appropriate use and security level. These levels can determine how and where data can be stored.
- Does your data need to be encrypted? Please contact the Chief Information Security Officer for assistance at ciso@boisestate.edu
- Do you need High-Performance Computing (HPC) capabilities for your research?
- Contact Research Computing Support for assistance with data transfer and virtual storage.
Context Capturing
How do I get people to communicate through shared systems to capture institutional/project knowledge?
The context for file management often exists in informal channels, such as emails, phone calls, off-hand conversations, and other hard to capture mediums. In order to combat the issue of lost context, teams may establish shared systems, for instance networked drives or cloud spaces, but these systems are only useful if the people involved utilize them.
Worker motivation is an extensively studied and published upon field that relates to any desired action, including using shared systems as part of a knowledge management plan. There is no one way to get your team to participate, but keep these guiding principles in mind:
Outline the Benefits of Context Capturing
- Refer to the introductory segment of this page for good talking points. Have team members discuss times they wished a project had better context. Why was the context lost? Explain how this context capturing plan will mitigate those situations.
Set Reasonable Expectations
- Unless there are legal or policy requirements, it is not feasible that every casual communication will be recorded. As a team, complete the self-reflection exercise to establish what types of context should be captured, when, and how.
Provide Sufficient Support
- Do team members need additional training to effectively meet expectations? Are the technologies used sufficient or would a different application be more efficient? Be open to team member concerns about ease of use, additional time required, and the added value of completing the process.
Provide Constructive Feedback
- Schedule regular times to check in, especially early in the process, and review how well context is being captured. Avoid punitive measures and instead highlight anyone who is participating well.
Iterate
- It is impossible to foresee every need or issue that will arise. Don’t be afraid to adjust the process as needed, but remember to communicate these changes to the entire team.
How do I figure out what my access needs will be over time?
Begin by reviewing any legal or policy requirements. Does your organization, funder, or department require access to certain types of information for specific periods of time? For example, Institutional Review Boards will usually mandate that human subject research data be kept for a specific number of years. You should retain materials that capture context for at least as long as you are required to keep the actual records.
If there is no mandated retention period, consider the nature of the project or materials and use the self-reflection exercise to guide you. Use the examples your team shared when outlining the benefits to inform what types of information your team tends to need access to, post-project completion. Consider questions such as:
- Who needs access currently? How likely is that to change?
- Do I have resources that allow me to easily provide long-term storage or access? If I do not, how difficult would it be to acquire these resources?
- Where does this information fit in my organizational structure? (i.e. Is this information unique to my team or department? Is it cross-departmental? Does it affect the entire organization?)
Why do I need to capture context?
Capturing context related to the project can lessen confusion regarding decisions made by the team. This can be crucial on projects where team members cycle on and off a project over time, such as in a university research lab.
How do I capture context?
The mechanics of capturing context will depend on your team and available tools. It may be as simple as printing and scanning emails to create a PDF record of communications that is more widely available. It may be as complex as audio recording and subsequently transcribing all meetings in order to have a word for word record of all proceedings. When capturing context use the same best practices you would employ when capturing data:
- Use file formats that are the least proprietary and most likely to have long-term accessibility.
- Use consistent file naming that clearly delineates the files as contextual documents and what part of the project or organization they relate to.
- Utilize security and storage backup protocols; you may even want to consider additional duplication or backup efforts if the contextual documents would help you recreate a project or institutional knowledge in the event of a catastrophic loss.
- Reference contextual documents in your read me files.
What context should I be capturing?
It is important to distinguish context from data, information, or knowledge. The Cambridge Dictionary online defines context as “The situation within which something exists or happens, and that can help explain it.” Essentially, if your data, information, organizational knowledge, etc. cannot be understood by an outside or future party, you probably need to capture some level of context. Consider the following examples:
- A research team collects in-person, on-campus, survey data every year in December. One year they experience record snowfall and only collect half as many responses as they normally do. Another researcher, using the data years later cannot understand why the group gathered such a small sample size for one year.
- A departmental “Request for Change of Classroom” form includes several checkboxes asking about niche technologies that no faculty in the department currently use. No one can remember why these boxes were added to the form or whether it would be okay to remove them.
- A college’s research funding policy includes many awkwardly written sentences. A revision committee suspects that they were written this way for a reason, but do not know what it is and are hesitant to change them without understanding their background.
How does capturing context help me do my work?
Sometimes the benefits of context capturing are not immediate. Instead, context capturing is a preventative measure that can help you do your work days, weeks, months, or years after critical decision making. In addition to explaining how and why decisions were made a certain way, context capturing can describe actions that were attempted and did or did not work.
What is a “ReadMe” and why do I need it?
A “ReadMe” file is study or organizational level documentation that includes general overviews of information, content descriptions for related files, data attributes (if appropriate), and identifier and rights information. In relation to context capturing, it is important to reference any context summaries or reports in your ReadMe file.
You can find more details on the ReadMe Files page.
Metadata Standards
- Metadata can be thought of as a way of reporting on your data and is beneficial in helping others find and use your data.
- If you are looking for a possible metadata schema to use with your own project, consider this list from the Digital Curation Centre in the United Kingdom: List of Metadata Standards or this list from the Research Data Alliance: Metadata Directory
System Considerations
File management tools and capabilities will vary based on your operating system (Windows, Mac, Linux) or cloud-system (Dropbox, Google Drive, OneDrive) preference. Considerations for choosing a system include:
- Your need for multiple people to edit documents at the same time (Google Drive is good for this, depending on the level of data security you need)
- Your need to access documents from multiple devices (Consider using a cloud-based system like Google Drive or setting up VPN)
- Your familiarity with GUI (Windows or Mac) or Command Line (Linux)
- The level of security needed (Google Drive is approved by Boise State’s OIT at certain levels)
Whichever operating system your team utilizes, we recommend researching the full functionality of the tools and specifically searching for ways to add metadata and organize. For example, there are strategies for forcing a file naming convention in Microsoft Word.